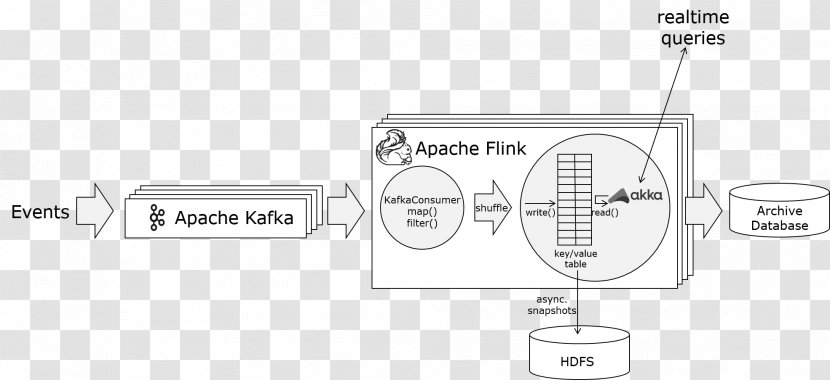
A diagram that shows the process of creating an Apache Kafka file. It consists of two boxes, one labeled "Apache Kafka" and the other labeled "Archive Database". In the center of the diagram, there is a circular diagram that represents the Apache Flink file, which is a type of file that is used to store and access data from a database. The file is connected to the Apache Kafka database by a series of arrows. The arrows indicate the flow of data between the two boxes. On the left side of the image, there are two boxes labeled "Kafka Consumer Filter" and "Key Value Table". On the right side, it is labeled "HDFS". This indicates that the file is stored in an archive database, which allows the user to access the data stored in the file. The image also shows a key value table, which can be used to calculate the value of the file in the archive database.
User profddds uploaded the image
User profddds uploaded the image
Apache Spark Big Data Kafka Scalability - Material - Stream PNG
. The resolution of this PNG file is 1970 x 904 pixels and it has a file size of 67.09 KB.Apache Spark Big Data Kafka Scalability - Material - Stream PNG
You might also like these images below...