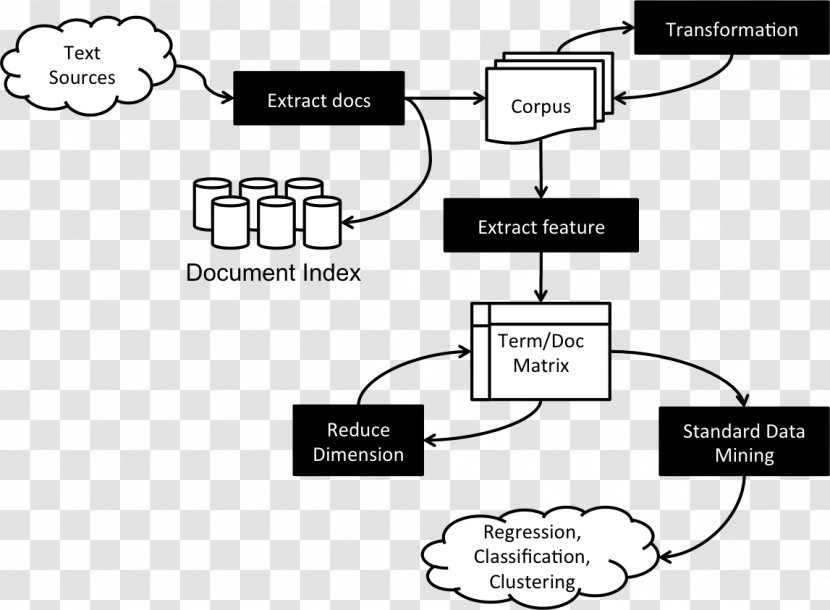
A diagram that shows the process of transforming text sources into different types of data. There are four main components in the diagram:
1. Text sources:
2. Extract docs
3. Corpus
4. Extract feature
5. Reduce dimension
6. Regression, Classification, Clustering
7. Standard Data Mining
8. Term/Doc Matrix
9. Transformation
The diagram is divided into four sections, each representing a different type of data source. The first section is labeled "Text Sources" and shows a stack of text with the word "Corpus" written on it. The second section is titled "Extract feature" and has a label that reads "Extracted feature". The third section is labelled "Standard Data Mining". At the bottom of the diagram, there is a label with the words "Regression", "Classification", and "Clustering". This suggests that the image is related to the process in which the data source is extracted from a document or a document.
User brethemd uploaded the image
User brethemd uploaded the image
Text Mining Data Document - Analytics PNG
. The resolution of this PNG file is 1147 x 843 pixels and it has a file size of 91.77 KB.You might also like these images below...